I have a lot of conversations with customers about security and compliance. These conversations typically run along the following lines:
- I want a report of what content my users can access.
- I want to audit the activities of my users on their content.
- I want to protect my content by limiting access to where it resides.
These are good, traditional approaches to security and compliance. Control what content users and groups have access to, then monitor the actions they take on what they have access to, and lastly, secure the folder or library that the content lives in.
Yet, in the past few years, a new approach to data security has emerged: DCAP, short for Data Centric Audit and Protection.
By “Data Centric”, you re-orient your controls based on the data in the content itself, not on the users or the places the content is stored. “Audit” means you are auditing security events based on the content, not on the users. “Protection” means that the steps taken to protect the content are based on the data it contains, regardless of where it lives.
Put another way, rework that list above:
- I want a report of what kinds of data are in my content.
- I want to audit the activities of my users based on the data in my content.
- I want to protect my content based on the data it contains.
For more detailed descriptions, check these links in Digital Guardian and in CIO Magazine.
Put in plain language, here are some examples to illustrate the DCAP approach.
- I want to label as “sensitive data”, any file that has a social security number. I also want to label as “GDPR”, any content that has data matching GDPR definitions.
- I want to produce a report over what actions were taken on any files that were labeled “sensitive data”. Optionally, maybe I only care about”modify” events.
- I want to apply sophisticated access controls on any content labeled “sensitive data”, but otherwise, I don’t want to interfere in access to content.
If you look at the first examples I put forward, you’ll notice that two of them are user-centric.The difference is: do I care about what my users can do, or what’s being done with my content?
I’ve avoided getting into any specific platforms or solutions so far. Whether your files are hosted on file shares, SharePoint, in a cloud storage service, or somewhere else, these concepts apply.
Furthermore, these concepts are not mutually exclusive. A robust security protocol will have aspects of both. Where user-centric helps keep tabs on your users, data-centric helps you protect content based on what’s actually in it, not what you think is in it.
What about that third item I mentioned at the top, “I want to protect my content by limiting access to where it resides.”
If you think back to the early days of files in folders on file shares, the easy way to protect content was to put it into folders, and then share the folders based one who you thought should have access. You might have a “shared to all” folder, a “department” folder, and maybe a “sensitive data” folder. Put controls on the folders, and all the contents are safe.
If you extend that concept into what modern collaboration platforms like SharePoint are capable of, nowawdays we might also rely on a user to label content. We relied on them to put content in the correct place, right? Sensitive content goes here, and also gets a label of “sensitive” to let everyone else know, and that’s it. Right? RIGHT?
The problem with this approach is twofold. First, we’re still relying users to do the right thing: to put sensitive data in the right folder, and to label it as sensitive. People are fallible, therefore this approach is not reliable. Second, if we’re relying on content to be secured by where it lives, we’re taking a rather ham-fisted approach to data classification: “everything here should be secured in the same way”.
Imagine a system that could automatically classify content based on the data inside it. Something that could identify credit card numbers, or social security numbers, or any items from a list of cities, religions, or other personally identifying information. If it finds something, it labels that as sensitive.Or, at least, imagine something that could prompt users to classify a document, ala, “it looks like there are some social security numbers here, you might want to label this as sensitive”.
Returning to the audit question, imagine if you had a system that could give you an idea not only of how many files with sensitive data you had, but how those files compared to one another? A file with a single social security number might be a problem, but a file with a hundred social security numbers would be a much bigger problem.
This is called risk scoring, and can expanded in other ways. Classification might be based on multiple criteria,but some criteria could be more important than others; weighted scoring. Rather than receive alerts based on every single red flag, you allowed a certain amount of risk, but wanted extra eyes on the riskier content? Risk thresholds.
I’ve written previously in detail about Microsoft’s approach to labeling, including Sensitivity and automatic labeling. In the not-too-distant future I’ll post about some other solutions and approaches.
Bonus Round: Driving multiple processes with Data Centric Audit & Protection
As I mentioned at the top, I have a lot of conversations with customers about data security and compliance. However, if you haven’t guessed by now, those words can have slightly different meanings to different teams, and the purpose of classifying content may vary from team to team.
Let’s start with a basic set of files, and their contents spelled out.
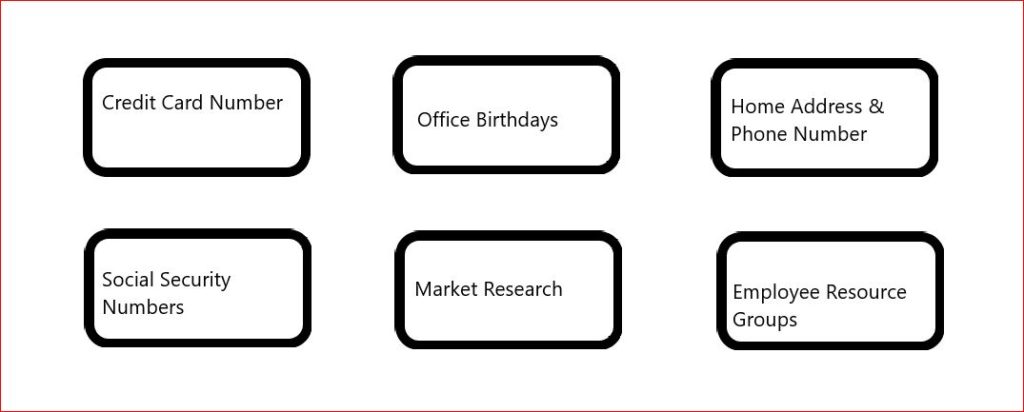
The first thing anyone might say is, “holy cow we need to label this,” like so.

Yay! Now we’ve labeled our content. Anyone handling this content will know, hopefully, that sensitive content might require more care in sharing, proprietary should get out to the public or a competitor, and non-sensitive maybe it’s not a big deal if it leaks.
Larger organizations will have a formal classification scheme for classifying data; the above three-layer nomenclature is just an example. Some organizations have additional classifications, others, different names. For optimal performance, inform your users what these terms mean, and when to use them.
All that aside, labeling content in itself is inconsequential. It’s what we do once a label has been applied, that counts.
An information security person might look at these labels and say, “we need an information policy that limits Sensitive data to be opened up on company devices, and Proprietary data needs to prevent access unless on the company network”.
A records management person might say, “I’m less concerned with sensitivity – I want to make sure we don’t retain credit cards and socials longer than necessary, and I don’t care about birthdays, but we do need to hold onto home addresses and phone numbers for regulatory reasons, and the Employeer Resource Groupss, just in case a dispute comes up.”
Voila – retention labels. Remember the difference? In any case now we’re applying two labels based on the data in this content, because we are Data-Centric.

That’s great. But then comes along the Privacy Officer, who says, “we need to be concerned about Data Subject Access Requests. What if lil’ Joey Smith-Jones files a Right to be Forgotten request?”
We can identify what those requirements amount to, and label content something like “DSAR” to help us find it later.

So now we have that label. We have three different labels, supporting or driving multiple processes.
If we were relying on folders to organize these files, we’d have multiple, redundant folders:
- Sensitive/NoRetain/NoDSAR
- Sensitive/NoRetain/DSAR
- Sensitive/Retain5/NoDSAR
- Sensitive/Retain5/DSAR
. . .and so on. At least with labels, these files can all live in the same place. If we add various controls and processes based on their labels, we’ve automated outcomes, and if we further automate the labeling itself, based on the data in the content, we have a robust, scalable, repeatable classification scheme that meets our needs to security, retention, and privacy.